77% of enterprise AI usage are using models that are small models, less than 13b parameters.
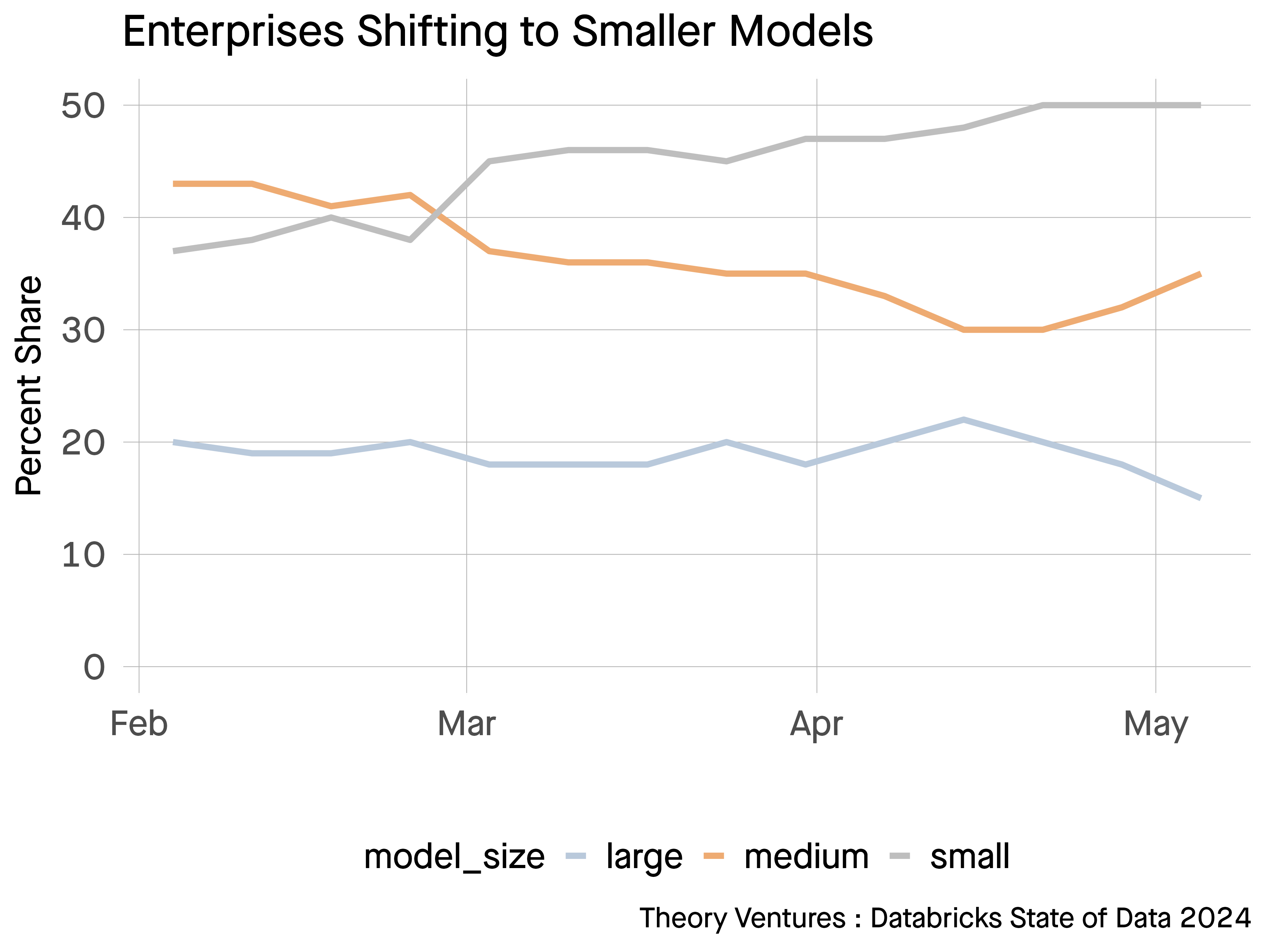
Databricks, in their annual State of Data + AI report, published this survey which among other interesting findings indicated that large models, those with 100 billion perimeters or more now represent about 15% of implementations.
In August, we asked enterprise buyers What Has Your GPU Done for You Today? They expressed concern with the ROI of using some of the larger models, particularly in production applications.
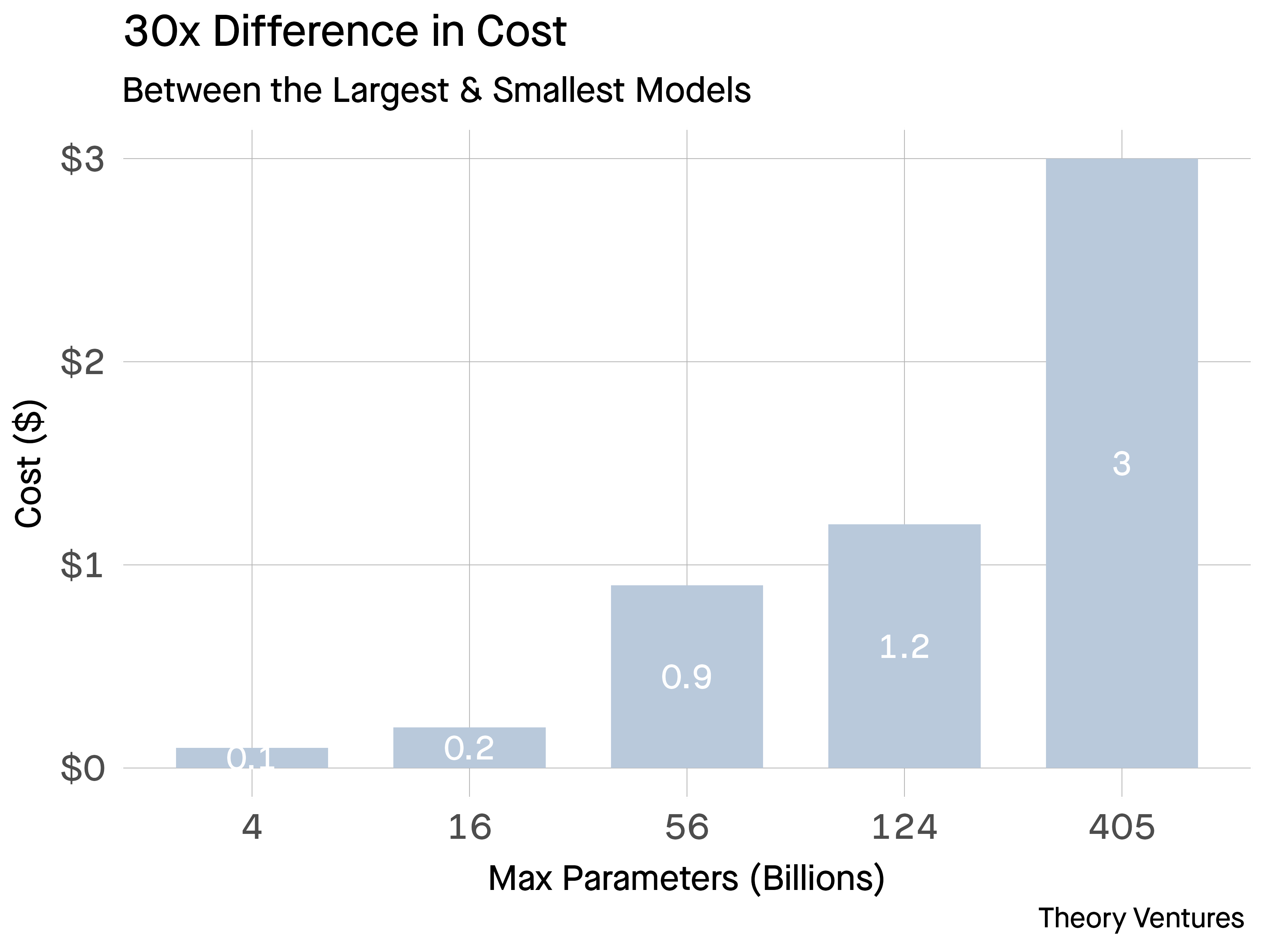
Pricing from a popular inference provider shows the geometric increase in prices as a function of parameters for a model.1
But there are other reasons aside from cost to use smaller models.
First, their performance has improved markedly with some of the smaller models nearing their big brothers’ success. The delta in cost means smaller models can be run several times to verify like an AI Mechanical Turk.
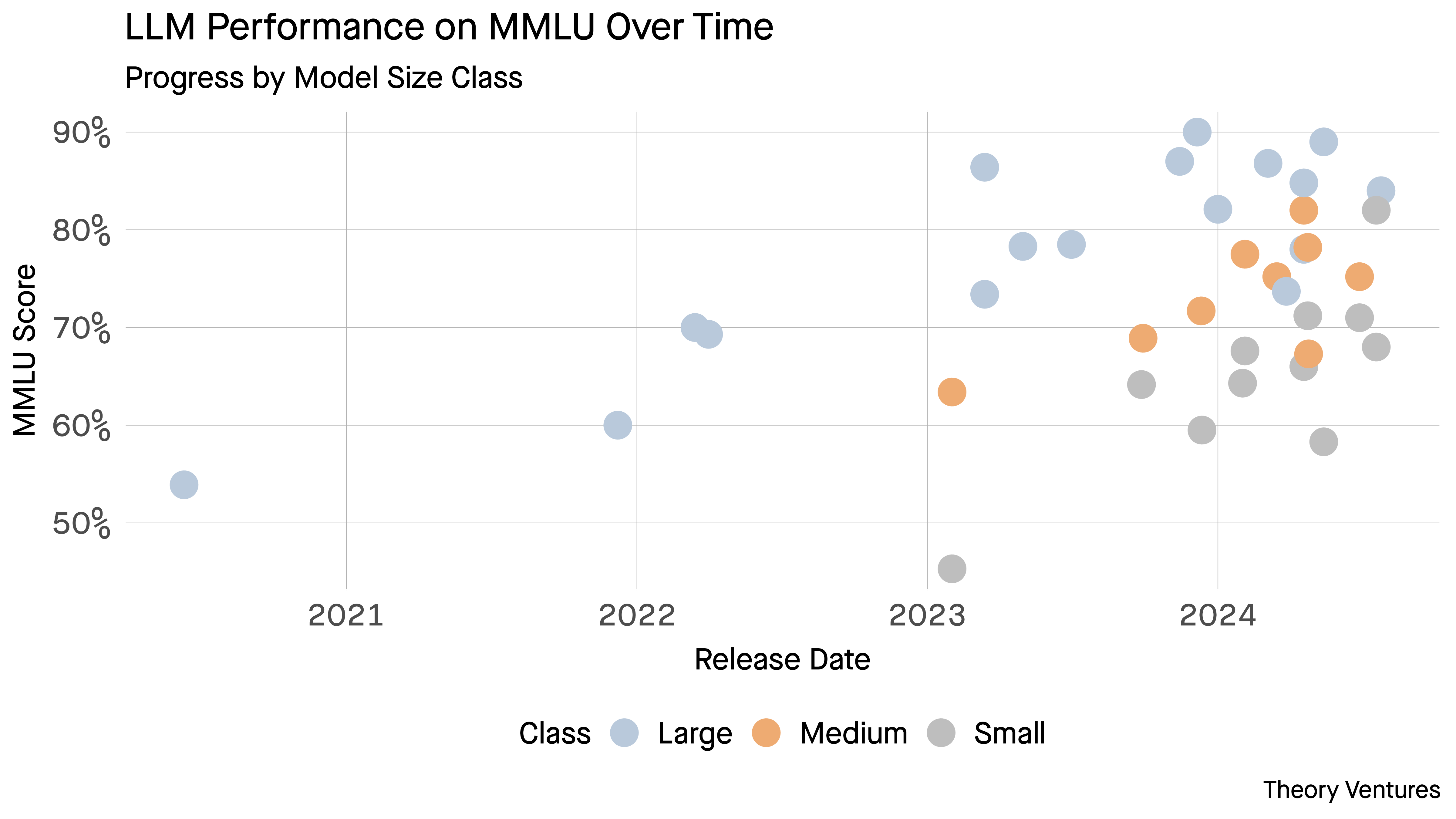
Second, the latencies of smaller models are half those of the medium sized models & 70% less than the mega models .
| Llama Model | Observed Latency per Token2 |
|---|---|
| 7b | 18 ms |
| 13b | 21 ms |
| 70b | 47 ms |
| 405b | 70-750 ms |
Higher latency is an inferior user experience. Users don’t like to wait.
Smaller models represent a significant innovation for enterprises where they can take advantage of similar performance at two orders of magnitude, less expense and half of the latency.
No wonder builders view them as small but mighty.
1Note: I’ve abstracted away the additional dimension of mixture of experts models to make the point clearer.
2There are different ways of measuring latency, whether it’s time to first token or inter-token latency.